Continuum Type Initial Pitch Correction
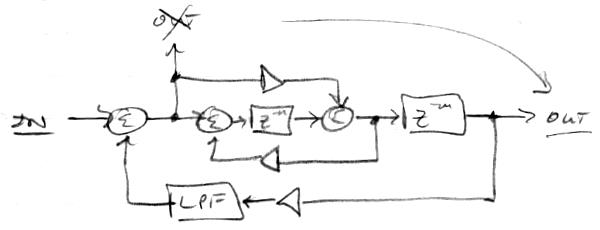
Yesterday something made me think of the Haken Continuum, which got me to thinking about what I imagine is the initial pitch method on it. With a continuous controller like the Continuum, Theremin, violin, trombone, etc, the player 99.9% of the time desires that a given note start its life sounding on-pitch, rather than off-pitch. The Continuum has the advantage here of real attack type actions happening on the playing surface to guide the pitch algorithms, whereas the Theremin generally doesn't. On the D-Lev, however, one can fairly simply arrange things in SW so that when the volume drops below audibility the pitch correction becomes more aggressive. I implemented this today and the results are quite encouraging. Here is a view of the entire current pitch correction datapath: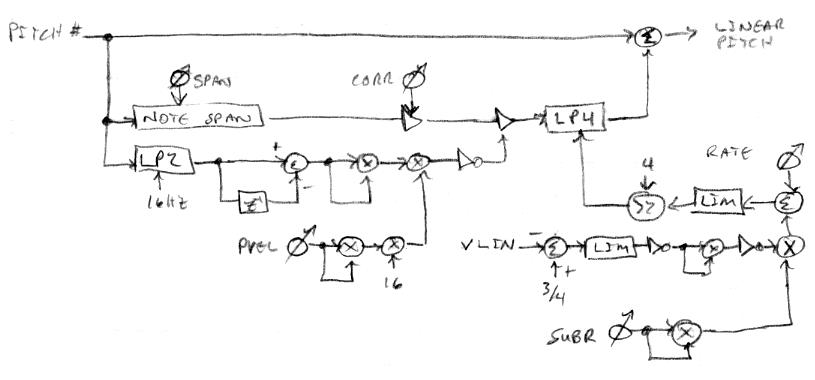
The section to the upper left is unchanged from before: There are three paths for the linear pitch number, the top path is the unmodified pitch number, the middle path expands each note to full scale and selects a portion of it to correct (span knob) with a certain strength (corr knob), the bottom path is 2nd order low-pass filtered (16Hz), and it then modulates the middle path with pitch hand velocity squared and a given variable influence (pvel knob). The final middle path is 4th order low-pass filtered and combined with the top path as a feed-forward error correction signal.
The section to the lower right is new: The linear volume number is subtracted from 3/4, which establishes the threshold of audibility as -48dB, the result is limited, inverted, squared, and inverted, which gives a "hump" like shape below the -48dB point. The strength of this is controlled via a squared parameter (subr knob), then combined with another parameter (rate knob), limited, and scaled by 1/16 to control the cutoff frequency of the 4th order low-pass filter. This raises the filter frequency between notes, which lowers the settling time of the applied correction (the whole point).
I thought of modulating the pitch velocity with this scheme as well, which would make the correction below audibility more aggressive in the presence of high velocity strength settings (high pvel), but after playing with it for a while that seems unnecessary. You can easily see it working if the tuner is set to post pitch correction, and you can easily hear it working if the pitch preview is enabled and set to "wheedle" when the playing voice is below audibility. Otherwise, it's impossible to tell that anything is going on - other than that you are suddenly a somewhat better player! Provided of course that your pitch hand is actually indicating the correct note "regions" at the time of their play. These pitch quantization schemes do have downsides, and one of them is that they can make certain kinds of mistakes worse. But, hey, don't set the knobs too crazy. And (I assume) Continuum players have to contend with this sort of thing too (really sloppy playing + overly aggressive correction = big boo-boos).
[EDIT] Here's a sample where it's turned all the way up and you can hear the pitch preview stepping between notes, but the notes themselves smoothly gliss: [MP3]. It does seem to improve my playing. I have no idea if this would be useful / too aggravating for those who rely on pitch preview, though it can be turned down to be less "steppy" sounding yet still lend accuracy to the initial phase of notes.