Volume Envelope Knee
Sometimes I'm stymied by what seems like a simple problem. When that happens I often find that utilizing the visual centers of my brain will get me through it much faster. I always do this with digital design: I draw the logic pipeline, and then some waveforms associated with it - sort of a paper sim of critical functionality before I implement the real thing in SystemVerilog.
With the Theremin assembly code I'm up against modulo math a lot, and drawing graphs of the various steps makes it much clearer. For example, I wanted to add a variable "knee" or downward slope to the volume envelope to make the vocal transition more realistic. At first I looked at the obvious geometric ways to do this (x intercept, slope, etc.) but in the end it was much easier to generate a separate sloped signal and subtract this from the volume response:

Above we see the volume response 'X', which is linear, on the left. The point 'T' is where we desire the break or knee. If we subtract 'X' from 'T' we get the center response, and if we multiply this by 'K' we get something that hinges about 'T' at the x axis. We can then subtract this from the original input to get our knee response. All of these operations are full-scale 32 bit, and saturating math is used throughout. I have many of these functions in the integer library I wrote, and it would be great if I could include them in the Hive op codes as they seem to get used a lot, but I have doubts that the Hive pipeline would allow it.
So the volume processing side is now:
operating point acquisition => filtering => linearization => velocity envelope => knee => attack / decay via slew limiting => EXP2 => to stuff
I find that placing the knee before the attack / decay lets me soften the decay knee a bit in time, which sounds more realistic from a vocal perspective. Voice often jump-starts, but then later can taper off below the starting level. I wound up sharing the variable threshold 'T' knob between both the velocity envelope and knee functions, as the double-duty seems to make sense here.
===============
DSP Architecture
I'm still pursuing the goal of designing the signal path for vocal sim first, and anything else that's easy after that. I've developed all the modules for the following architecture, and have had most of it up and running for a while now:
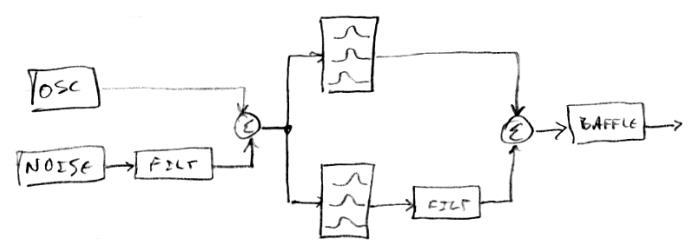
On the left: I need to add volume axis and possibly pitch axis modulation to the oscillator harmonic content adjustment. The noise has a dedicated filter because it usually can't be used raw, even if it is being processed by the formant bank. In the center: there are two formant banks, the top one is for nose and throat radiation, the bottom one is for mouth radiation. The filter following the lower one is for lip modulation. On the right: the formants are summed and we can do final stuff like baffle simulation. Then we ship it to the SPDIF module for D/A conversion.
I've currently got 6 formant bandpass filters, though voice sounds fine to me with just 4 (2 + 2 in the above plan). They might benefit from a bit of volume axis / pitch axis modulation to their center frequencies. It's easy to go crazy on this stuff and provide an adjustment for everything, but then you end up lost in a sea of screen menus. Looking for a sweet spot of maximal flexibility with minimal control.






