Past Another Hump
Woke up at 1:30 am with an idea for the multiplier and just had to see if it panned out. Ended up using it in the sim but not the hardware core (>64 bit math is not standard to C++ so I had to generate the 65th multiplication bit manually given the various signed / unsigned input scenarios - because the inputs are 33 bit sign/zero extended, it's basically 0 for U*U, and the 64th result bit for mixed U*S, S*U, S*S). Spent all day writing verification assembly and tracking down a few bugs. Sim and core both verify, it's nice having the same thing described in two different languages as it catches a lot of mistakes / bad ideas (though it's a trifle disorienting switching between C++, SV, and Hive assembly). Just finished recoding the sections of Theremin and library code which aren't supported anymore. Notably, immediate logical AND, OR, and XOR are gone. I never used immediate OR or XOR, and only used the immediate AND a few times here and there. Immediate extended arithmetic operations are also gone due to infrequency of use. Even though I used it a fair amount, I removed the reverse subtract - it always kinda bugged me, as an odd man out it never really fit in the encoding, and there are various two cycle replacements. The core SV code compiles and meets timing, but I don't have the courage today to do the FPGA pump. Best to quit and declare victory while one is ahead!
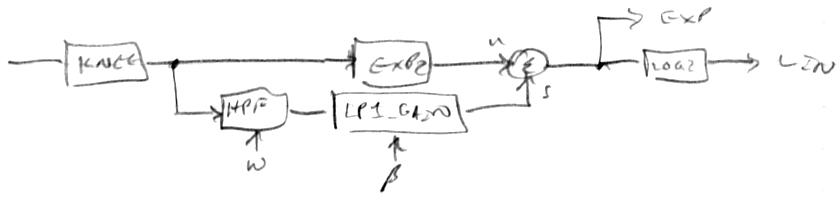
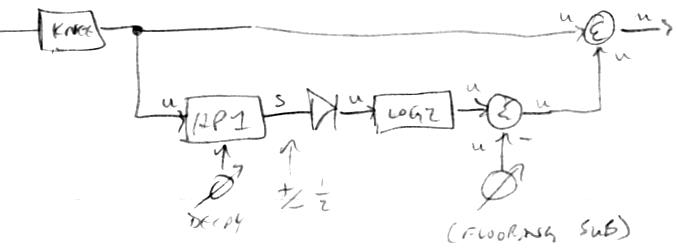
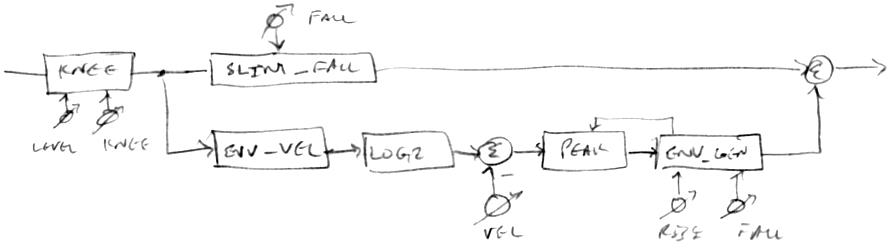
With the addition of travelling flags, it feels like the core is in a basically better and more interesting place, though I haven't gone through and replaced all of the limiting / saturating subroutine code with the new and more efficient opcodes yet - will do that once I've got it all back up and running in a stable fashion. One thing at a time, debugging time seems to increase exponentially with the number of changes applied at once. Churn like this at the lowest level upsets the whole house of cards, and while I haven't hit a bug yet that I could lick in a day or two, the possibility of that kind of bad luck is always present. Flirting with disaster is my middle name...
[EDIT] Moron seems to be my middle name today. Was trying to track down a stack push bug and forgot to do the "Assembler: Generate Programming Files" step in Quartus, the FPGA tool. So it wasn't at all obvious that the software load wasn't changing with my edits. The bug was on thread 7, which is the command line thread, so I couldn't upload new SW loads the usual way, so I had to re-pump the FPGA each time and do a non-SPI Flash boot.
In my defense, there are many steps to the SW build process:
1. Fire up the Hive simulator, or do a "cfg" command in it, which translates HAL assembly to MIF.
2. Run "copy.bat" file on my desktop to copy the 4 MIF files to the FPGA Hive source directory.
3. In Quartus do a "Processing | Update Memory Initialization Files".
4. In Quartus do a "Assembler: Generate Programming Files". (Doh!)
5. In Quartus do a "File | Convert Programming Files..." select the *.cof file (which automates this) and click "Generate".
6. In Quartus open the programmer and run it (also largely automated).
When the command line is working I only have to do step 1, then run TeraTerm and send the generated TTL macro to the FPGA, which programs the SPI and reboots the Theremin.
I have a core version number I can read in the register set via the command line to confirm the SV firmware pump, and I really should have an easily readable software version somewhere as well.
Anyway, it's all back up and running like it was before I started monkeying with things. Now to clean up the library code a bit. I can't think of anything else I might want to change or add to my Hive processor, it's feeling kinda done and I'm pretty happy with it.
[EDIT2] Removed all the manually implemented saturation / limit subroutine calls, which has reduced and streamlined several functions. Having a two step saturation / limit allows you to add, multiply, and especially subtract (which isn't commutative) with the same move flexibility as a 3 operand machine, which is quite nice.
There are real down sides to "kitchen sink"-ing the opcode space. Leaving certain out ones (like leading zero count, byte flipping, etc.) which take many operations to implement can hurt you in specific scenarios, so you should include those (anything that speeds up floating point operations, or if you have to deal with endianness, should be included if possible). But ones that you only use now and then, and which can be implemented in two steps with other ops, should probably be removed. I think people often think of theses things in terms of AMD vs. Intel benchmarks, and how a slight performance difference in one or more seems like certain market success / death, but they're shoveling tens of millions of transistors at those benchmarks for very small improvements, and creating something so complex no one fully understands them so there are bugs, security holes, and assorted gotcha's everywhere. It's kind of crazy, even fairly modest software and processors are enormous shaky state machines running on enormous shaky state machines, and the whole thing is only manageable because of a huge amount of automation (it's enormous shaky state machines all the way down).
And another thing: we all do it I suppose, but isn't it weird to rely on the error reporting of the compiler when modifying your code? It's a testament to how well error reporting works, though it's easy to miss important editing details. My assembler halts on the first error it encounters, which generally pinpoints the issue well, though generally not when it's a scoping error (I notice the C++ compiler I'm using also has problems pinpointing scoping errors). But scoping is much too useful to not implement / employ. The C++ compiler doesn't halt on first error, but rather insists on finding a huge pile of them before giving up, whereupon I fix the first one and recompile. Kind of a time waster IMO, particularly since the subsequent cascade of errors tend to be due to the first few. Though I suppose in certain debugging scenarios it's critically important to examine as much error info as possible.